
You have most likely arrived here after reviewing the Quickstart guide, if not it is recommended to start there.
Mapping is the process of annotating the fields in a data source with terms Senzing understands, this informs Senzing what the data in the fields represents and how to use that data when performing entity resolution. Put simply, for example, it's telling Senzing the data in column 5 should be treated as a first name and the data in column 10 should be treated as a phone number
Mapping
To begin mapping click on the MAPPING button on a data source card in your project.
Name your Data Source
On the mapping screen give your data source a unique and descriptive name, this is used to identify where loaded records have come from. For example, if the data source you are mapping contains customer data a good choice would be CUSTOMERS.
Selecting Attribute Types
For each column in the data source that will be used for entity resolution you need to inform Senzing what the data in the column represents. For example, the column that contains a personal last name may be named lname in your data source. The corresponding term that Senzing understands to determine the data represents a last name is NAME_LAST. The process of mapping is selecting the correct term for the data in each column.
You will find the application maps many data source columns automatically. Your task is to accept or correct the ones it mapped automatically and manually assign the ones not auto-mapped or not mapped correctly.
Click on Mapped to to reveal categories each with a list of terms under them. It is these terms you select to inform Senzing what type of data is in each column. Consider the example of a column with last name data, you would select the NAME category and the NAME_LAST term for that column.
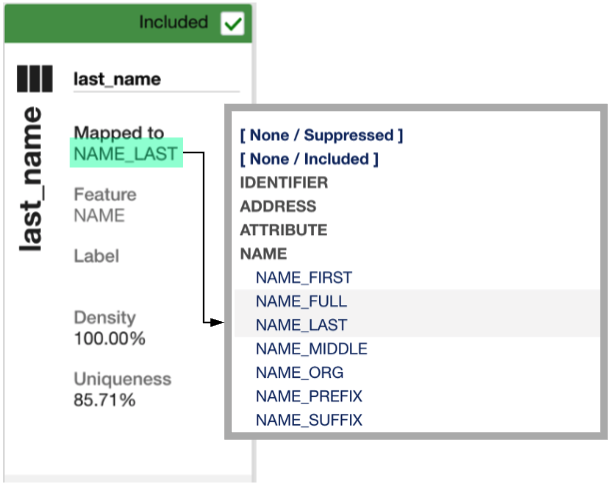
The Mapped to pull-down list is grouped by category. There are common terms for names, addresses, phones, identifiers like drivers license, passport and email addresses, and other attributes like date of birth and gender. It’s a good idea to familiarize yourself with this list.
Repeat this process for each column that contains identity data to be used for entity resolution.
Using Labels
Labels are used to group attributes that belong to a feature when there is more than 1 feature of that type. For example, a data source contains two addresses, one address is the primary residence and the other a secondary residence such as a holiday home. To ensure the address attributes for each address group together a label is specified as part of the mapping. Assume each address is mapped to ADDR_LINE1, ADDR_CITY, ADDR_STATE and ADDR_POSTAL_CODE, each of these receives a label such as PRIMARY which informs Senzing they are grouped together. You would do the same for the secondary address using a label such as SECONDARY. You can choose the label to use but it's useful to be descriptive to differentiate each one when reporting.
To add a label locate the columns to label, click on Label, enter your label and click Save.
The use of labels is true for other attributes too such as names. Consider having 2 names in a data source you would use labels in a similar way to group the individual name attributes together; one labelled LEGALNAME and the other AKA, for example.
Labels are useful for reporting too. If you have multiple phone numbers (or other attributes) labels can be applied to let you know what type of phone number it is. Useful labels might be HOME and MOBILE.
Including Other Data
You may have data in your data sources that is needed for reporting but not used for entity resolution, for example a status code or value amount.
To include or exclude a data source column, check mark the Included box at the top of the column. In this example, setting the customer_since column to None/Included indicates you'd like to ingest this column and make it available for reference, but it will not be used for entity resolution as it is not mapped to a valid Senzing term.
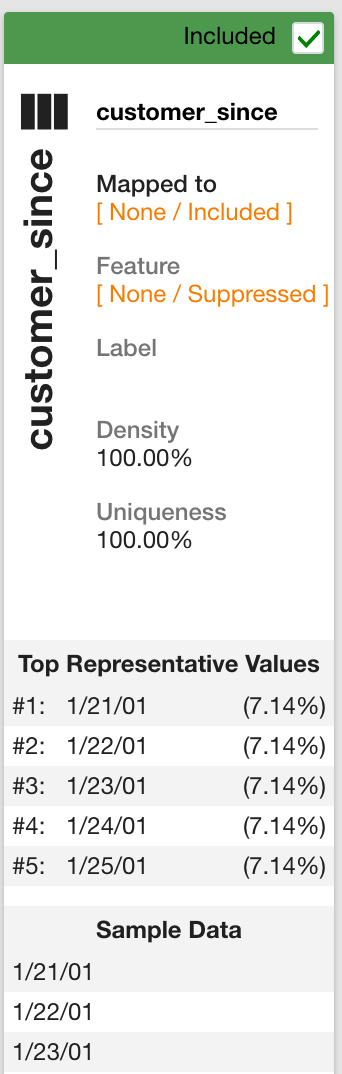
Ideally, you wouldn't include every un-mapped column from a source, especially columns with a large amount of text in them as they will make your reports harder to read. You can always reference the source system and view the full details of all fields that are not relevant and used by entity resolution.
Mapping Guidance
During the mapping process guidance messages may pop up to help guide you to resolve issues, these are color coded:
- Red Alerts are issues that will prevent entity resolution from taking place
- Yellow Alerts are warnings that indicate possible problems
- Blue Alerts highlight best practices you might choose to follow
Ready to Load
Once you have completed the mapping process and there are no guidance messages preventing loading, click the Ready to Load button and load your data sources as outlined in the Quickstart guide.
Comments
0 comments
Please sign in to leave a comment.