
Entity Resolution (ER) is the process of grouping or clustering records into sets that belong together. These sets are referred to as entities and usually the records pertain to persons or organizations, but they could really be anything: vehicles, vessels, asteroids, etc.
Many of the concepts and algorithms used here were based on the following paper ... http://honors.cs.umd.edu/reports/hitesh.pdf
Different algorithms will likely group the records differently. The G2Audit tool was designed to compare ER results from either different "runs" of a static record set, or from a postulated set of groupings referred to as a "truth set"
Consider the following graphic ...
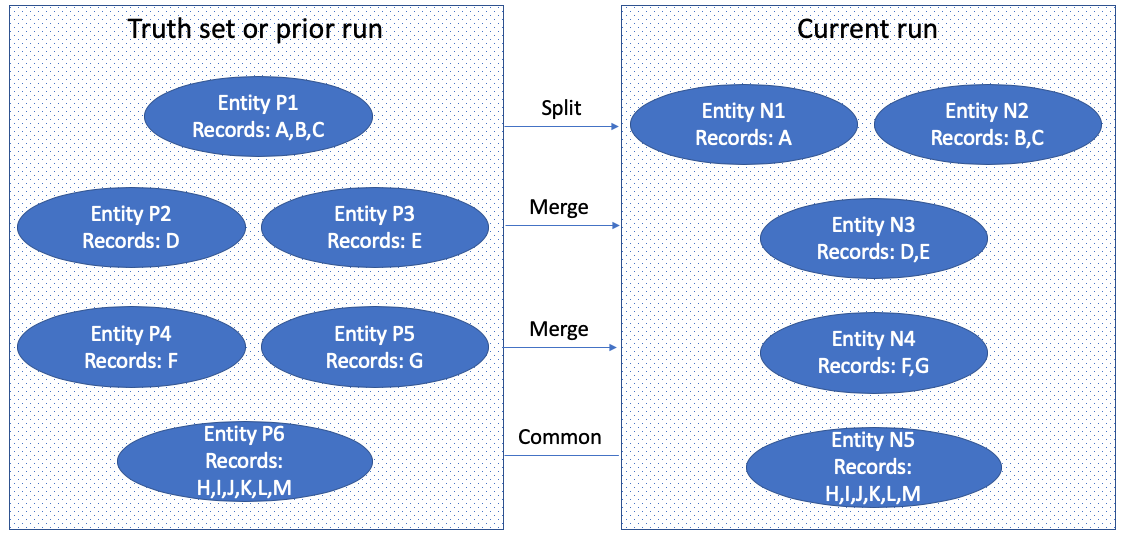
- The prior run has six Entities while the newer run has five.
- There are 18 Prior positives in the prior run based on a pairwise calculation that yields ...
- entity P1 has 3 pairs (AB, AC) and (BC)
- entities P2-P5 are singletons and have no pairs
- entity P6 has 6 records which count as 15 pairs: (HI, HJ, HK, HL, HM) and (IJ, IK, IL, IM) and (JK, JL, JM) and (KL, KM) and (LM).
- The current run Split entity (P1) into entities (N1 and N2) creating two new negatives. This is because P1 has 3 pairs and the largest split entity, N2, only has 1 pair (BC)
- The current run Merged entities (P2 and P3) into entity (N3) creating one new positive.
- The current run Merged entities (P4 and P5) into entity (N4) creating one more new positive.
- Both the current and prior run grouped the same records in entities (P6 and N5), so they have one entity in Common.
The terms new positive and new negative are used to accommodate comparing runs with or without a truth set. Consider that one run's false positive is another run's false negative. It is also sometimes the case that when reviewing a truth set, the postulated positive or negative is itself proven to be false (or at least acceptable) and the truth set gets corrected.
Statistical Analysis
There are three broadly recognized computations that can be applied to truth set comparison.
- Precision: The formula for precision is prior positives / (prior positives + new positives)
- The more “new positives” found, the lower the precision score.
- Recall: The formula for recall is prior positives / (prior positives + new negatives)
- The more “new negatives” introduced, the lower the recall score.
- F1 Score: The formula for F1 Score is 2 * (Precision * Recall) / (Precision + Recall)
- This a blended score that helps you identify the best overall score.
When comparing multiple runs against a postulated truth set, the best run would be the one with the highest F1 score even though the losing run may have a higher recall score and a lower precision score. Of course these statistics are presented for your review. If you place more emphasis on recall than precision, you might pick the run with the highest recall as long as the lower precision is acceptable.
When comparing the runs of two different engines when there is no postulated truth set, remember one engine's new positives are the other's new negatives. In this case, the scores just tell you how close the runs are to each other. You would then browse the entities that were split or merged to see which you agree with most. For instance, if you basically agree with the splits in the second run, you would consider they were false positives in the first run.
When comparing the effect of configuration changes in the same engine, consider that you are making the configuration change to get more matches (reduce false negatives) or less matches (reduce false positives). For instance, if you expected 10% more matches, the precision should be in the 90s. If its in the 80s, you got 20% more matches! And hopefully you didn't lose any of the prior matches so the recall should still be 100. If it dropped as well, you lost prior good matches!
Browsing the differences
While the precision, recall and F1 pertain to records, its easiest to review the split and merged entities. Therefore the following statistics are also computed ...
- Prior count - the number of entities in the prior run
- Newer count - the number of entities in the newer run
- Common count - the number of entities in common
- Split - the number of entities that were split
- Merged - the number of entities that were merged
- Overlapped - the number of entities that had both splits and merges
The comparison of the record sets in the graphic above results in the following chart ...
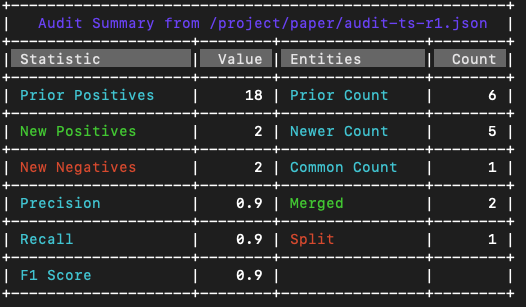
Note that the two new positives affected two "merged" entities, whereas the two new negatives only affected one "split" entity. There are no "overlapped" entities in this analysis.
All splits, merges, and overlaps are presented from the prior run's point of view.
Comments
0 comments
Please sign in to leave a comment.