
Attached to this article is an example truth set file with the following columns ...
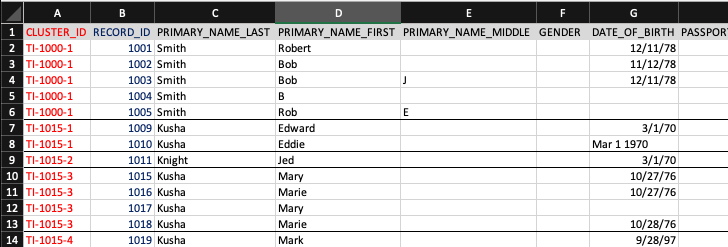
In the example file above …
- The red cluster_id column groups records that should resolve together. It is a purely made up alphanumeric value.
- The blue data_source and record_id columns are required by Senzing and form the unique key of a record. Please note: record_id’s must be unique within a data source!
- The black columns after record ID are the data fields for each record and must use our pre-defined column names described In this article Generic Entity Specification
The only thing a truth set really needs is a set of data with a unique record_id and a key which includes cluster_id and record_id. In the above example, the data and the key are combined into one file. However, the key with just those two columns can be in a separate file.
It is always preferable to use real data from your own operational systems when creating a truth set. If this is not possible, see the Creating Synthetic Data section below. Moreover, it is best to keep the truth set small for an accuracy test, i.e., well below 10,000 records.
Using Real Data – With Competing Entity Resolution Algorithms
One of the most efficient ways to create a truth set is to apply two entity resolution algorithms against the same set of real data. After running the same data through both engines, compare the results following these instructions Exploratory Data Analysis 4 - Comparing ER results to quickly find records that display a consensus among the algorithms, e.g., they all agreed on the match or non-match. While it is advisable to spot check these consistencies, it is likely these will be accurate matches. Add these to the truth set. Next, compare the matching discrepancies to identify more records that should and should not resolve.
Using Real Data – With One Entity Resolution Algorithm
If there are not competing entity resolution engines to accelerate the development of a truth set, a single engine can be used. In this case, one must perform a sample audit on the suggested matches. Be sure to select at least 100 hundred examples that both should and should not resolve. When testing for accuracy, records that should not match are just as important as records that should match. It is unfortunately common for truth sets to lack examples of close but invalid matches. To address this error and ensure these corner cases are not forgotten, we recommend adding two to ten times the number of harder matches to the consensus set of records that the entity resolution algorithms agreed upon initially.
Next, hunt for missed resolutions (i.e., false negatives). To do this most efficiently, simply review the possible matches and derived relationships that Senzing detects and records during entity resolution.
Creating Synthetic Data
Accuracy statistics on synthetic data rarely reflect true accuracy when using real-world data (unless you are using simplistic data across a limited number of data sources, a single data source being de-duplicated, data sets with few fields (e.g., name, address, phone) or have decent data quality).
If you must use synthetic data, there are a few ways to create it, and some are better than others.
The best option is to start with real records in your data that should and should not resolve. Then create handcrafted synthetic records, based on these records sets, and change essential elements (e.g., changing “Andrew Smith” to “Marcus Taylor”).
If no real-world examples are accessible, then all data must be fabricated. You should begin by inventorying your existing data sources to determine which fields are populated and examine details such as their sparsity, format and quality. For example, one data source might have a FULL_NAME field that is always empty. Another system may have a FULL_NAME that contains both “Mark E. Smith” and “Smith, Mark E.” representations. Be sure to also look for any foreign scripts in your data, such as Arabic or Chinese. If you need to test entity resolution on scripts with which you are not familiar, you will need to find someone who speaks that language to help.
Synthetic data generation programs exist to speed up data fabrication. These programs are helpful for creating high volumes of synthetic data for testing scalability. We do not recommend using them for accuracy testing because the accuracy results between this type of synthetic data and real life can swing widely.
It can be helpful to add columns that help you remember why you thought records should or should not match. You can name these columns anything you want. For instance, you might add a "test group" column to delineate a set of records that resolve into one or even two entities. An expected_result column can also help you remember what you expected to happen.
Maintaining a Truth Set
Your truth set will evolve over time. Every time you find an interesting example, add it to your truth set. Also, do not be surprised if you find flaws in your truth set, which will necessitate corrections to the truth set.
Comments
0 comments
Please sign in to leave a comment.